

We know that data is the fuel for AI. But how much data do we need to create an AI model? We often think that AI needs massive amounts of data to provide significant results. While this may be true in some cases, in many cases it is not. This article will discuss AI applications that can provide great value, even without having the ideal scenario of possessing all data available.
Data collection and gathering is difficult and expensive, and it is often the most time-consuming step in an AI project. Many contributing factors can lead to a lack of data. Financial or logistical constraints may be impeding your collection of data. In some cases, the data may be fragmented throughout many different spreadsheets, oftentimes in various formats that can be arduous and challenging to combine. Finally, in many cases, the data may simply not be available.
We may also have a situation where an attribute was not being collected when the AI model was created and, sometime later, this attribute became available. In this case, the AI model can start to be trained on the new attribute, along with the other attributes. As you can see, there are many situations where data is not available in the quantity and the variety desired but, we do not need to wait for the ideal scenario to get started with AI. The awesome thing is that AI can still provide great value, even when working with limited data. Let us find out how.
How many trips do you need to make from your home to your work to know how long it takes? Not so many, right? Similarly, it is not always necessary to have years and years of data to train an AI model. Of course, AI models are not perfect and there will always be room for improvement. As the famous statistician George Box said: “All models are wrong, but some are useful”. In every project, it is necessary to evaluate how confident your models must be to be useful. Going back to our home-to-work time prediction, you may take longer to get to work on rainy days. So, your prediction may be off on these days, and you may decide, down the road, to add precipitation as an attribute to your model. But let us stop here for a second. If you live in an area that only rains 30% of the days, you will still get an accurate prediction 70% of the time. I will leave it up to you to decide whether that is useful or not because the answer depends on each business situation. The point is that you do not need to wait for the ideal scenario to get some value out of AI.
Also, when you do need models that require intensive sampling to make an accurate prediction (such as trying to determine forest inventory), AI models can be trained on past inventory volume and on actual volume, along with other unit attributes, to “learn” the average inventory-actual variance for each unit condition. This provides a better estimation of the unit actual volume, which may even allow you to reduce the sampling intensity and, therefore, reduce your cost. Remsoft Operations currently offers an AI component that predicts the unit volume based on the Field Estimate and other unit attributes.
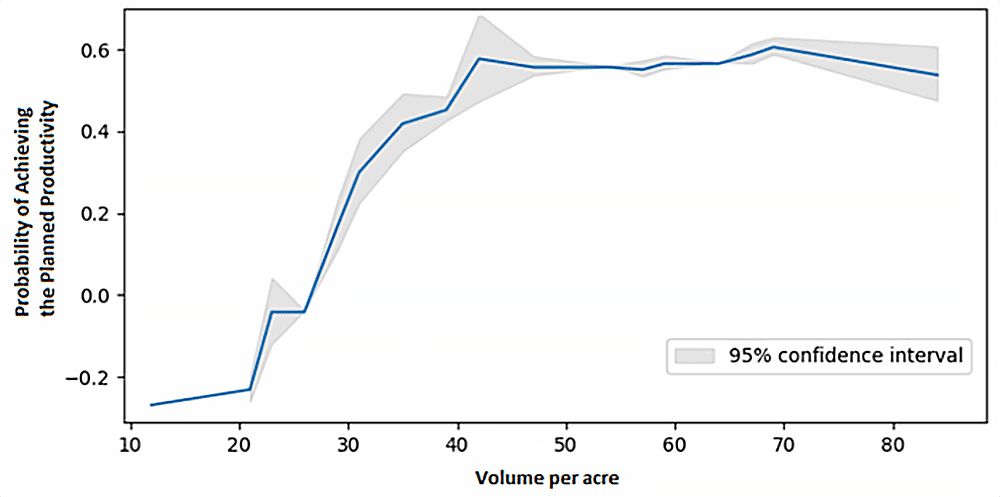
Even when you do not have all the necessary data to make a prediction that meets your accuracy expectations and requirements, you can still train a model to provide valuable insights. To mention a few examples, these insights may be the conditions where late assignments are more frequently seen; it could also be the assignments delay drivers, along with a better understanding of the tipping point of each attribute to cause a late assignment, in other words, at which point an attribute can cause an imminent risk of a late assignment. Sometimes the insights may even be just the probability of a late assignment. These alone provide tremendous value to any business, offering the opportunity to take a data-driven business decision.
In summary, data is indeed the fuel for AI, and yes, the more data you have, the more value you get out of AI. But that does not mean you cannot start getting value out of the data you currently have. Why wait for the ideal scenario if you could start now? Remsoft is proud to be a leader in AI and business intelligence for forest management planning.
LEARN MORE:
-
Read our article on how Optimization and Artificial Intelligence are helping to transform the forestry supply chain.
-
Book a demo to discover how AI and Optimization can help you maximize the value of your data to achieve greater efficiency and productivity.



