
Woodstock allows users to target reports to SQL Server databases, making model schedules and outputs readily available for use in other applications. However, scenarios pose a challenge. When Woodstock writes a report to a database table, it deletes all data in the table and repopulates it with report data from the scenario being compiled (see article 145 in the documentation system). Unless each scenario is connected to a distinct dataset—as done in Remsoft-developed solutions—the database report table will only contain data from the last scenario run.
To address this, you can direct reports to local files, merge them across scenarios into a single file, and use that file to update the database. This article outlines the process and provides some considerations when using this approach.
Process
Step 1. Generate reports
Begin by compiling scenarios to generate the necessary reports. Target these reports to either CSV or DBF format, ensuring consistency in file names and content across scenarios.
Step 2. Merge report files
Next, merge the reports across scenarios. You can access the Merge Report Files feature in the Reports section (see article 3093). Select a report, choose the scenarios to merge, and specify the file where the merged report will be stored.
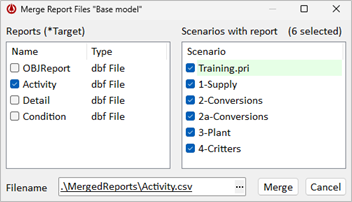
Here activity reports stored in DBF files from six scenarios will be merged into a single ‘Activity’ CSV file (DBF or SQLite are also options).
The merged file will include a ‘Scenario’ column storing the scenario name.
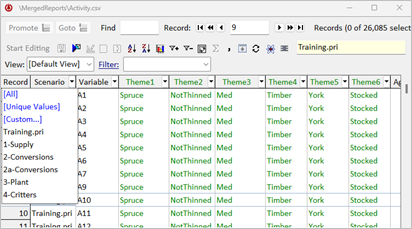
Step 3. Update the database
Finally, update the database with data from the merged report file using an Integrator script stored in the model template.
; Template PROCEDURES BEGINREGION Update Report Database BEGINMODELFILE Connection.ado Activity FOREACH xx in .\Merged\Activity.csv QUERY( Select * from Activity) .IF(xx.rec = 1,xx.allfieldnames,) xx.allfields ENDFOR ENDFILE ENDREGION
This requires the model to be connected to the database. The ‘Connection.ado’ referenced in the script stores the database connection string information (see article 1443). The merged report data is written to the ‘Activity’ table in the database, with the table schema derived from the field names and types in the CSV file. The script, declared in the Procedures section the template, can be accessed and executed directly from the Woodstock Editor.
You can add loops to the ‘Update Report Database’ region for other merged reports as needed.
Considerations
When using this approach, consider the following to avoid data conflicts or structural issues.
- Report Consistency Across Scenarios
Ensure that each scenario generates reports with identical file formats and column names. The report for the active scenario in the Editor determines the column names in the merged report file. Woodstock will notify you of any columns excluded from the merged file due to discrepancies. - Range of Models Stored in the Database
This approach is designed for use with a single model. If you plan to store report data from multiple models in the same database, it is advisable to use separate tables for each model. Because Integrator deletes all records in database tables before adding new data, processing models individually to the same table would result in only the last model’s data being saved. - Scenario Properties
The Merge Report Files feature automatically adds a ‘Scenario’ column to the merged file, but if different models use identical scenario names, distinguishing between them in the database could be difficult. To prevent ambiguity, consider including additional scenario properties to the base reports to identify the model it belongs to (see articles 3092 and 3009). - Database Table Schema Alignment
Woodstock updates data in existing database tables without dropping or recreating the table, so any changes made to the schema are preserved. However, to ensure successful updates, columns in the database table must match those in the merged report file, as only matching columns are updated. If data in reports change—you add or remove columns or data types change—you may need to change the schema for corresponding tables in the database. - Repeating updates over time
This update process deletes all records in the database table before adding new data. If you need to retain existing data, consider taking steps to prevent data loss. Options include modifying the table name in the update script to create a new table each time or backing up the database prior to each update to preserve historical data.
The process described here allows you to efficiently store and manage report data from multiple scenarios in a single database, minimizing data conflicts and ensuring accessibility across applications.




